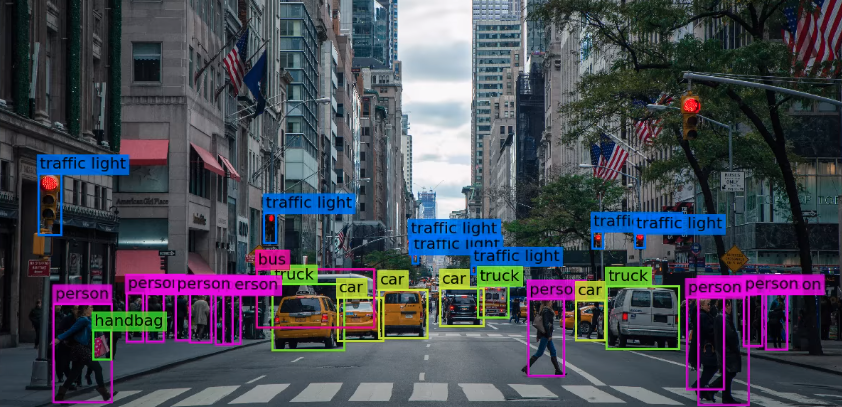
What is RF-DETR
RF-DETR is a real-time object detection transformer-based architecture designed to transfer well to both a wide variety of domains and to datasets big and small. As such, RF-DETR is in the "DETR" (detection transformers) family of models. It is developed for projects that need a model that can run high speeds with a high degree of accuracy, and often on limited compute (like on the edge or low latency).

Comparison
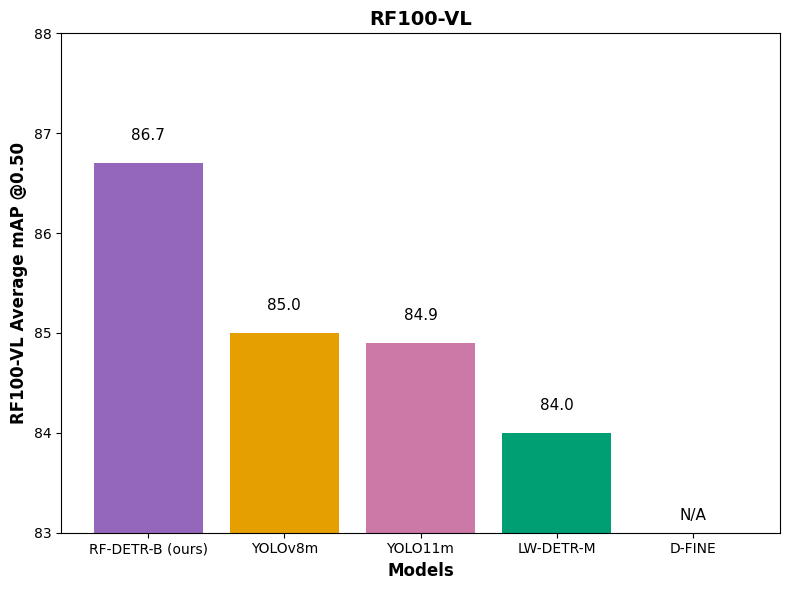
We evaluate RF-DETR relative to realtime COCO SOTA transformer models (D-FINE, LW-DETR) and SOTA YOLO CNN architectures (YOLO11, YOLOv8). With respect to these parameters, RF-DETR is the only model #1 or #2 in all categories.
Of note, the speed shown is the GPU latency on a T4 using TensorRT10 FP16 (ms/img) in a concept LW-DETR popularized called "Total Latency." Unlike transformer models, YOLO models conduct NMS following model predictions to provide candidate bounding box predictions to improve accuracy.
However, NMS results in a slight decrease in speed as bounding box filtering requires computation (the amount varies based on the number of objects in an image). Note most YOLO benchmarks use NMS to report the model's accuracy, yet do not include NMS latency to report the model's corresponding speed for that accuracy. This above benchmarking follows LW-DETR's philosophy of providing a total amount of time to receive a result uniformly applied on the same machine across all models. Like LW-DETR, we present latency using a tuned NMS designed to optimize latency while having minimal impact on accuracy.
Secondly, D-FINE fine-tuning is unavailable, and its performance in domain adaptability is, therefore, inaccessible. Its authors indicate, "If your categories are very simple, it might lead to overfitting and suboptimal performance." There are also a number of open issues inhibiting fine-tuning. We have opened an issue to aim to benchmark D-FINE with RF100-VL.
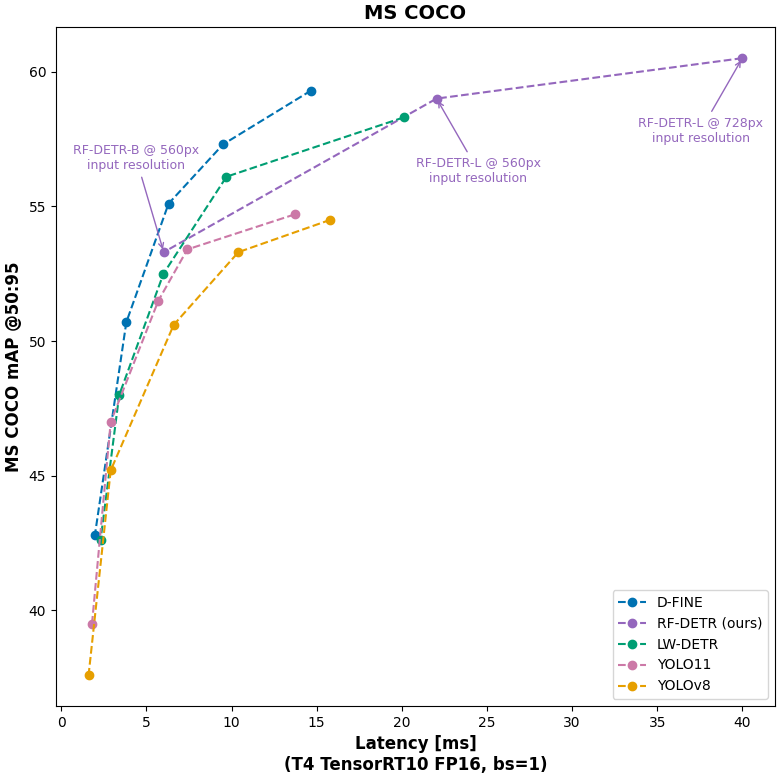
On COCO, specifically, RF-DETR is strictly Pareto optimal relative to YOLO models and competitive – though not strictly more performant – with respect to realtime transformer based models. However, in releasing RF-DETR-large and using a 728 input resolution, RF-DETR achieves the highest mAP (60.5) for any realtime (Papers with Code defines "real-time" as 25+ FPS on T4).
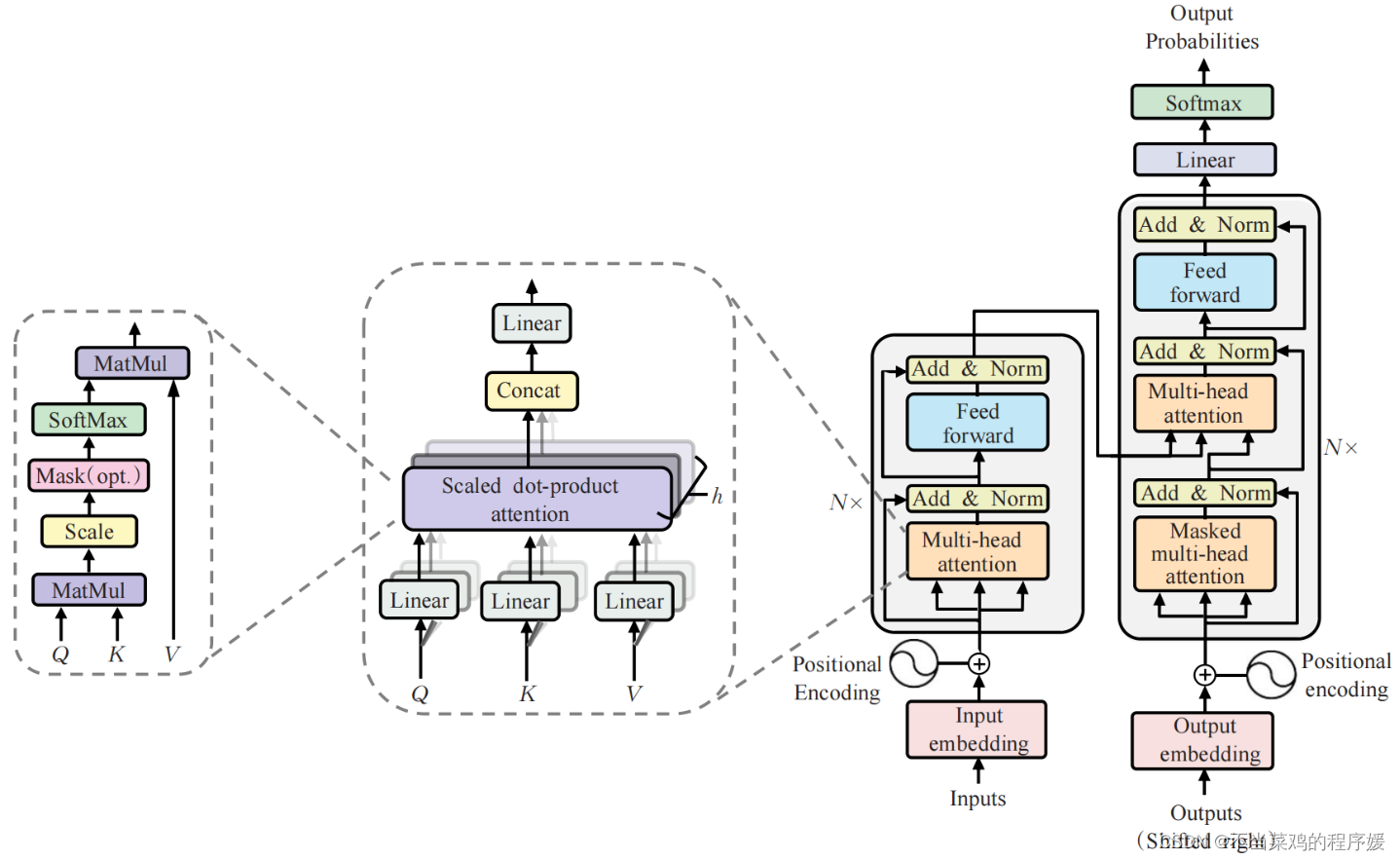
Architecture
Historically, CNN-based YOLO models have given the best accuracy for real-time object detectors. CNNs continue to be a core component of many of the best approaches in computer vision, e.g. D-FINE leverages both CNNs and transformers in its approach.
CNNs alone do not benefit as strongly from large scale pre-training like transformer-based approaches do and may be less accurate or converge more slowly. In many other subfields of machine learning, from image classification to LLMs, pre-training is more and more essential to achieving strong results. Therefore, an object detector that shows strong benefit from pre-training is likely to lead to better object detection results. However, transformers have typically been quite large and slow, unfit for many challenges in computer vision.

Recently, through the introduction of RT-DETR in 2023, the DETR family of models has been shown to match YOLOs in terms of latency when considering the runtime of NMS, which is a required post-processing step for YOLO models but not DETRs. Moreover, there has been an immense amount of work on making DETRs converge quickly.
Recent advances in DETRs combine these two factors to create models that, without pre-training, match the performance of YOLOs, and with pre-training, significantly outperform at a given latency. There is also reason to believe that stronger pre-training increases the ability of a model to learn from small amounts of data, which is very important for tasks that may not have COCO-scale datasets. Hybrid approaches are also evolving. YOLO-S merges transformers and CNNs for realtime performance. YOLOv12 also takes advantage of sequence learning alongside transformers.
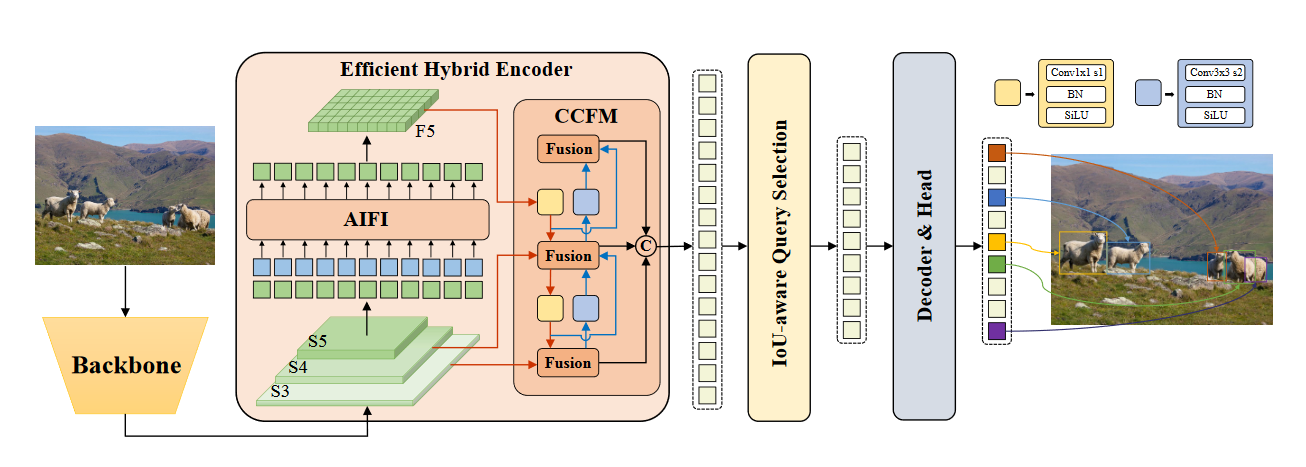
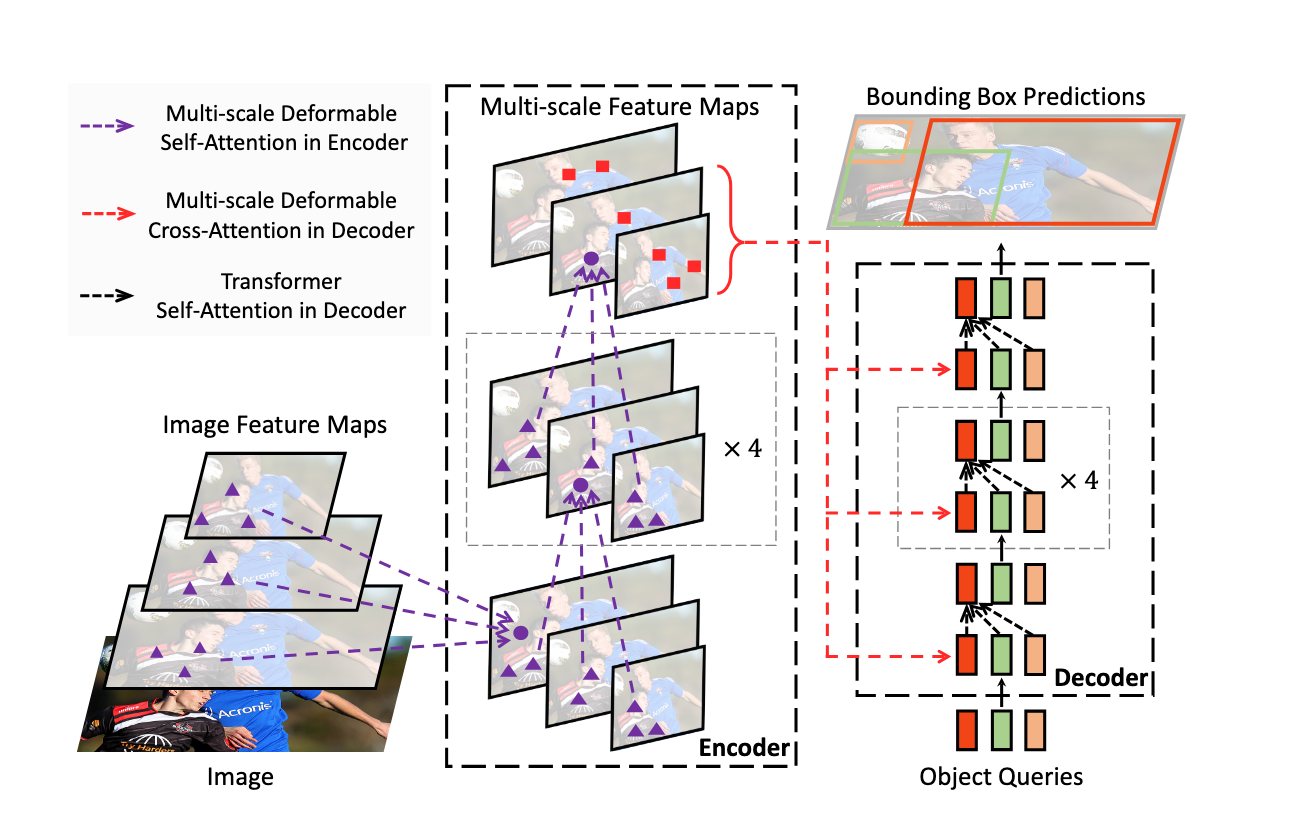
RF-DETR uses an architecture based on the foundations set out in the Deformable DETR paper. Whereas Deformable DETR uses a multi-scale self-attention mechanism, we extract image feature maps from a single-scale backbone.
How to use RF-DETR
Divided into the following phases
Training
Dataset structure
RF-DETR expects the dataset to be in COCO format. Divide your dataset into three subdirectories: train, valid and test. Each subdirectory should contain its own file that holds the annotations for that particular split, along with the corresponding image files. Below is an example of the directory structure:train valid test _annotations.coco.json
dataset/
├── train/
│ ├── _annotations.coco.json
│ ├── image1.jpg
│ ├── image2.jpg
├── valid/
│ ├── _annotations.coco.json
│ ├── image1.jpg
│ ├── image2.jpg
└── test/
├── _annotations.coco.json
├── image1.jpg
├── image2.jpgRoboflow allows you to create object detection datasets from scratch or convert existing datasets from formats like YOLO, and then export them in COCO JSON format for training. You can also explore Roboflow Universe to find pre-labeled datasets for a range of use cases.
Fine-tuning
You can fine-tune RF-DETR from pre-trained COCO checkpoints. By default, the RF-DETR-B checkpoint will be used. To get started quickly, please refer to our fine-tuning Google Colab notebook.
from rfdetr import RFDETRBase
model = RFDETRBase()
model.train(dataset_dir=<DATASET_PATH>, epochs=10, batch_size=4, grad_accum_steps=4, lr=1e-4, output_dir=<OUTPUT_PATH>)Different GPUs have different VRAM capacities, so adjust batch_size and grad_accum_steps to maintain a total batch size of 16. For example, on a powerful GPU like the A100, use and ; on smaller GPUs like the T4, use and . This gradient accumulation strategy helps train effectively even with limited memory.batch_size=16 grad_accum_steps=1 batch_size=4 grad_accum_steps=4
Resume training
You can resume training from a previously saved checkpoint by passing the path to the file using the argument. This is useful when training is interrupted or you want to continue fine-tuning an already partially trained model. The training loop will automatically load the weights and optimizer state from the provided checkpoint file.checkpoint.pth resume
from rfdetr import RFDETRBase
model = RFDETRBase()
model.train(dataset_dir=<DATASET_PATH>, epochs=10, batch_size=4, grad_accum_steps=4, lr=1e-4, output_dir=<OUTPUT_PATH>, )Early stopping
Early stopping monitors validation mAP and halts training if improvements remain below a threshold for a set number of epochs. This can reduce wasted computation once the model converges. Additional parameters—such as , , and —let you fine-tune the stopping behavior.early_stopping_patience early_stopping_min_delta early_stopping_use_ema
from rfdetr import RFDETRBase
model = RFDETRBase()
model.train(dataset_dir=<DATASET_PATH>, epochs=10, batch_size=4, grad_accum_steps=4, lr=1e-4, output_dir=<OUTPUT_PATH>, early_stopping=True)Multi-GPU training
You can fine-tune RF-DETR on multiple GPUs using PyTorch’s Distributed Data Parallel (DDP). Create a script that initializes your model and calls as usual than run it in terminal.main.py .train()
python -m torch.distributed.launch --nproc_per_node=8 --use_env main.pyReplace in the with the number of GPUs you want to use. This approach creates one training process per GPU and splits the workload automatically. Note that your effective batch size is multiplied by the number of GPUs, so you may need to adjust your and to maintain the same overall batch size.8 --nproc_per_node argument batch_size grad_accum_steps
Result checkpoints
During training, two model checkpoints (the regular weights and an EMA-based set of weights) will be saved in the specified output directory. The EMA (Exponential Moving Average) file is a smoothed version of the model’s weights over time, often yielding better stability and generalization.
Prediction
Single-image detection
The following code demonstrates how to perform object detection on a single image using RF-DETR.
import io
import requests
import supervision as sv
from PIL import Image
from rfdetr import RFDETRBase
from rfdetr.util.coco_classes import COCO_CLASSES
# Load the RF-DETR model
model = RFDETRBase()
# Load an image from URL
url = "https://media.roboflow.com/notebooks/examples/dog-2.jpeg"
image = Image.open(io.BytesIO(requests.get(url).content))
# Perform object detection
detections = model.predict(image, threshold=0.5)
# Generate annotation labels
labels = [
f"{COCO_CLASSES[class_id]} {confidence:.2f}"
for class_id, confidence
in zip(detections.class_id, detections.confidence)
]
# Draw bounding boxes and labels
annotated_image = image.copy()
annotated_image = sv.BoxAnnotator().annotate(annotated_image, detections)
annotated_image = sv.LabelAnnotator().annotate(annotated_image, detections, labels)
# Display results
sv.plot_image(annotated_image)Video detection
Here are professional translations for your video inference scenario:
import supervision as sv
from rfdetr import RFDETRBase
from rfdetr.util.coco_classes import COCO_CLASSES
# Load the RF-DETR model
model = RFDETRBase()
def callback(frame, index):
# Perform object detection on each frame
detections = model.predict(frame, threshold=0.5)
# Generate annotation labels
labels = [
f"{COCO_CLASSES[class_id]} {confidence:.2f}"
for class_id, confidence
in zip(detections.class_id, detections.confidence)
]
# Draw bounding boxes and labels
annotated_frame = frame.copy()
annotated_frame = sv.BoxAnnotator().annotate(annotated_frame, detections)
annotated_frame = sv.LabelAnnotator().annotate(annotated_frame, detections, labels)
return annotated_frame
# Process video files
process_video(
source_path="input_video.mp4", # Input video path
target_path="output_video.mp4", # Output video path
callback=callback
)
Real-time camera detection
You can also perform real-time object detection via camera.
import cv2
import supervision as sv
from rfdetr import RFDETRBase
from rfdetr.util.coco_classes import COCO_CLASSES
# Load the RF-DETR model
model = RFDETRBase()
# Initialize camera
cap = cv2.VideoCapture(0)
while True:
success, frame = cap.read()
if not success:
break
# Perform object detection on each frame
detections = model.predict(frame, threshold=0.5)
# Generate annotation labels
labels = [
f"{COCO_CLASSES[class_id]} {confidence:.2f}"
for class_id, confidence
in zip(detections.class_id, detections.confidence)
]
# Draw bounding boxes and labels
annotated_frame = frame.copy()
annotated_frame = sv.BoxAnnotator().annotate(annotated_frame, detections)
annotated_frame = sv.LabelAnnotator().annotate(annotated_frame, detections, labels)
# Display results
cv2.imshow("Webcam", annotated_frame)
# Press 'q' to quit
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
